Vous avez une facture générée dynamiquement, un email HTML à archiver ou une page web à capturer, et le PDF obtenu ne ressemble pas à l'original. La conversion HTML vers PDF semble simple. En pratique, les CSS sautent, les polices changent et les images disparaissent.
Ce guide couvre toutes les méthodes disponibles, du plus simple (votre navigateur) au plus puissant (scripts automatisés), pour que vous choisissiez la bonne selon votre cas d'usage réel.
Quelle méthode choisir pour convertir un fichier HTML en PDF ?
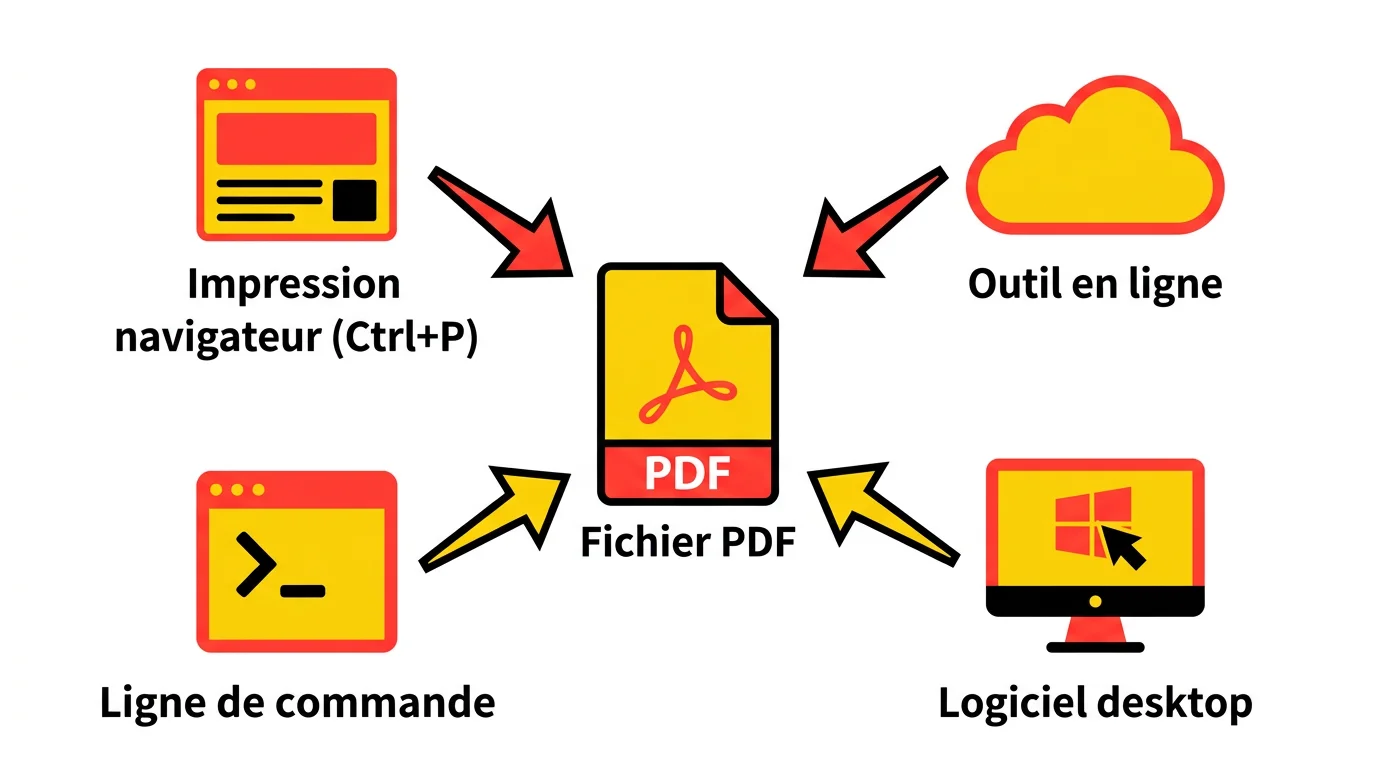
Il existe quatre grandes familles de méthodes : le navigateur natif, les outils en ligne, les logiciels desktop et les solutions programmatiques (CLI ou bibliothèques). Le navigateur convient aux conversions occasionnelles sans installation. Les outils en ligne gèrent des fichiers isolés rapidement. Les logiciels desktop donnent plus de contrôle sur le rendu. Les outils CLI permettent l'automatisation et le traitement par lot.
Le choix dépend surtout de votre contexte : convertissez-vous une page de temps en temps, ou des centaines de documents chaque semaine ? Avez-vous du CSS complexe, des polices personnalisées, du JavaScript ? Le format PDF lui-même, défini par le standard PDF ISO 32000 depuis 2008, impose des règles de rendu que les outils interprètent avec plus ou moins de fidélité. Consultez le comparateur interactif plus bas pour filtrer les outils selon vos critères précis.
Comparateur - Conversion HTML vers PDF
Filtrez les outils selon vos besoins et trouvez la meilleure solution
Filtrer les outils
La méthode navigateur : Ctrl+P, zéro logiciel requis
Pour convertir un fichier HTML en PDF sans rien installer, votre navigateur suffit. Ouvrez votre fichier HTML dans Chrome (ou Firefox, ou Edge), appuyez sur Ctrl+P (Cmd+P sur Mac), sélectionnez "Enregistrer en PDF" et validez. Gratuit. Instantané. Aucune dépendance.
Chrome : la référence pour un rendu fidèle
Chrome est de loin le navigateur qui produit les PDF les plus fidèles au rendu écran. Son moteur Blink gère correctement la majorité des CSS modernes : flexbox, grid, variables CSS. Pour de meilleurs résultats, désactivez les en-têtes et pieds de page dans les options d'impression. Et cochez absolument "Graphiques d'arrière-plan" si votre page utilise des couleurs ou images de fond.
Dans les paramètres avancés, vous pouvez ajuster les marges (aucune, minimale, par défaut ou personnalisée). L'option "Aucune marge" est utile si votre HTML gère déjà ses propres marges via CSS. Pour les documents avec contenu dépassant la largeur de la page, l'option "Mise à l'échelle" réduit automatiquement.
Firefox et Edge : des alternatives valables
Firefox génère des PDF de bonne qualité, avec un respect correct du CSS. Son avantage : il gère mieux certaines polices système et affiche parfois les tableaux plus proprement que Chrome. Edge, basé sur Chromium, produit des résultats quasi identiques à Chrome et ajoute une fonctionnalité utile, la possibilité d'annoter le PDF directement avant de l'enregistrer.
La limite commune à tous les navigateurs : ils ne gèrent pas les fichiers HTML locaux avec des ressources externes (polices Google Fonts, images hébergées ailleurs) si la connexion internet est absente. Dans ce cas, il faut intégrer les ressources en base64 ou utiliser un outil dédié. Pour adapter finement le résultat, les règles CSS pour l'impression, documentées par MDN, donnent un contrôle précis sur les marges, les sauts de page et les éléments à masquer.
Étape par étape : convertir avec Chrome
- Ouvrez votre fichier HTML dans Chrome (glissez-le dans l'onglet ou utilisez Fichier > Ouvrir)
- Appuyez sur Ctrl+P pour ouvrir la boîte de dialogue d'impression
- Dans "Destination", sélectionnez "Enregistrer au format PDF"
- Dépliez "Autres paramètres" pour accéder aux options avancées
- Cochez "Graphiques d'arrière-plan" si votre page utilise des couleurs ou images de fond
- Ajustez le format (A4 par défaut), l'orientation et les marges selon votre besoin
- Cliquez sur "Enregistrer" et choisissez l'emplacement du fichier PDF
Cette méthode fonctionne bien pour des conversions ponctuelles. Elle atteint ses limites dès que vous devez convertir plusieurs fichiers à la suite ou automatiser le processus.
Outils en ligne pour convertir du HTML en PDF
Les convertisseurs HTML vers PDF en ligne permettent de traiter un fichier sans installer quoi que ce soit, directement depuis le navigateur. Vous uploadez votre fichier HTML (ou collez une URL), l'outil génère le PDF en quelques secondes et vous le téléchargez. Pratique pour un besoin ponctuel, moins adapté aux volumes importants ou aux documents contenant des données sensibles.
Les outils gratuits qui s'en sortent vraiment bien
iLovePDF est l'un des plus connus. Il accepte les fichiers HTML uploadés ou les URLs de pages web. Le rendu est correct pour des pages simples. La version gratuite impose des limites de taille de fichier (25 Mo) et n'autorise pas le traitement par lot.
PDFCandy propose une interface simple et des conversions rapides. Il gère bien les CSS basiques mais peut trébucher sur des mises en page complexes avec des polices personnalisées. Sejda est une alternative solide avec une limite généreuse (200 pages, 50 Mo) en version gratuite. Convertio, de son côté, se distingue par sa compatibilité avec de nombreux formats d'entrée et son intégration avec Google Drive et Dropbox.
Ce que vous devez vérifier avant d'envoyer vos fichiers
Avant d'utiliser un outil en ligne, jetez un œil à leur politique de confidentialité. La plupart suppriment les fichiers uploadés après quelques heures, mais certains les conservent plus longtemps. Pour des documents contenant des données personnelles (factures, contrats, données clients), préférez une solution locale ou auto-hébergée. Des suites comme Adobe Acrobat Pro proposent à ce titre un environnement maîtrisé, sans envoi de fichiers vers des serveurs tiers.
Vérifiez aussi si l'outil accepte les ressources externes (polices, images via URLs absolues) ou seulement les fichiers autonomes. Un fichier HTML qui référence des ressources locales (images en chemin relatif) produira un PDF avec des images manquantes si l'outil ne peut pas y accéder. Une fois le PDF généré, partager le fichier obtenu avec des services comme SwissTransfer évite les problèmes de taille liés aux pièces jointes email.

Tableau comparatif des outils en ligne
| Outil | Gratuit | Lot | Limite taille | CSS avancé | Confidentialité |
|---|---|---|---|---|---|
| iLovePDF | Oui (limité) | Premium | 25 Mo | Moyen | Suppression 2h |
| PDFCandy | Oui | Non | 10 Mo | Basique | Suppression 1h |
| Sejda | Oui (3 tâches/h) | Non gratuit | 50 Mo | Bon | Suppression 2h |
| Convertio | Oui (100 Mo/j) | Non gratuit | 100 Mo | Bon | Suppression 24h |
| HTML2PDF.co | Oui | Non | 5 Mo | Basique | Non spécifiée |
| PDF24 | Oui, illimité | Oui | Illimité | Moyen | Suppression 1h |
wkhtmltopdf, Puppeteer et les outils CLI : conversion par lot et automatisation
Pour convertir des dizaines ou des centaines de fichiers HTML en PDF de façon automatisée, les outils en ligne de commande et les bibliothèques de code sont la seule vraie option. wkhtmltopdf, Puppeteer et leurs équivalents permettent d'intégrer la conversion dans un pipeline de génération de documents, un script cron ou une application web. J'utilise ces outils quotidiennement pour générer des rapports. Faire ça à la main prendrait une journée entière. Avec un script, c'est l'affaire de quelques secondes.
wkhtmltopdf : le couteau suisse de la conversion CLI
Le wkhtmltopdf outil open source, basé sur le moteur WebKit, s'installe sur Linux, macOS et Windows et s'intègre facilement dans des scripts shell, Python, PHP ou Ruby. La commande de base est simple : wkhtmltopdf input.html output.pdf.
Ses options avancées couvrent la quasi-totalité des besoins : définir le format de page (--page-size A4), les marges (--margin-top 10mm), ajouter en-têtes et pieds de page (--header-html header.html), gérer les sauts de page, activer JavaScript (--enable-javascript), ou encore définir un délai d'attente pour les pages dynamiques (--javascript-delay 2000). Pour la conversion par lot, un simple script shell boucle sur tous les fichiers HTML d'un dossier :
for f in *.html; do
wkhtmltopdf "$f" "${f%.html}.pdf"
doneLa limite principale de wkhtmltopdf : son moteur WebKit est basé sur une version ancienne (Qt 5), ce qui signifie que certaines fonctionnalités CSS modernes (grid complexes, certaines animations, variables CSS dans des contextes spécifiques) ne sont pas toujours bien rendues. Pour des pages web modernes, Puppeteer est souvent plus fiable.
Puppeteer : Chrome headless pour un rendu fiable
Puppeteer est une bibliothèque Node.js qui pilote Chrome ou Chromium en mode headless (sans interface graphique). Puisqu'il utilise le vrai moteur Chrome, le rendu est identique à ce qu'on verrait dans un navigateur, CSS modernes inclus. Pour des pages HTML complexes, c'est ce que j'utilise en priorité.
Un script de base pour convertir un PDF en PowerPoint ou vers d'autres formats passe souvent par cette même chaîne d'outils : un script qui injecte les données dans un template HTML, puis Puppeteer pour la conversion finale.
const puppeteer = require('puppeteer');
async function htmlToPdf(inputPath, outputPath) {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(`file://${inputPath}`, { waitUntil: 'networkidle0' });
await page.pdf({
path: outputPath,
format: 'A4',
printBackground: true,
margin: { top: '10mm', bottom: '10mm', left: '10mm', right: '10mm' }
});
await browser.close();
}
htmlToPdf('/chemin/vers/input.html', '/chemin/vers/output.pdf');L'option waitUntil: 'networkidle0' attend que toutes les ressources réseau soient chargées avant de générer le PDF. C'est indispensable pour les pages qui chargent des polices ou des images via des requêtes asynchrones. L'option printBackground: true est l'équivalent de "Graphiques d'arrière-plan" dans Chrome, à activer pour les pages avec couleurs de fond.
Playwright : l'alternative moderne à Puppeteer
Playwright, développé par Microsoft, a une API similaire à Puppeteer mais supporte Chrome, Firefox et Safari. Pour la génération de PDF, il s'utilise avec Chromium et produit des résultats identiques. Son avantage sur Puppeteer : une meilleure gestion des pages qui chargent lentement, et une API plus moderne avec des sélecteurs plus expressifs.
Pour des équipes qui font déjà du test d'intégration avec Playwright, réutiliser la même bibliothèque pour la génération PDF est un choix cohérent. Je préfère garder un seul outil dans la chaîne plutôt que de mixer. Cela dit, si vous partez de zéro pour de la génération PDF uniquement, la documentation Puppeteer reste plus fournie et les exemples plus nombreux.
Bibliothèques dans d'autres langages
En Python, la bibliothèque weasyprint est la référence. Elle supporte HTML et CSS 2.1/3, génère des PDF de qualité sans dépendance à un navigateur headless. Son atout : elle est pure Python, donc facile à déployer sur des serveurs sans interface graphique. pdfkit est un wrapper Python autour de wkhtmltopdf, plus simple à utiliser si wkhtmltopdf est déjà installé.
En PHP, dompdf est la solution la plus répandue. Elle génère des PDF directement depuis du HTML/CSS, sans dépendance externe. mPDF est une alternative avec un meilleur support des caractères UTF-8 et des langues avec écriture de droite à gauche. En Java, Flying Saucer et IronPDF sont les options les plus utilisées en contexte d'entreprise.
CSS print : comment contrôler le rendu de votre PDF ?
Le CSS @media print est ce qui sépare un PDF potable d'un PDF qui pique les yeux. Ces règles s'appliquent uniquement à l'impression (ou à la conversion PDF), sans toucher à l'affichage écran. Préparez votre HTML correctement, et le résultat sera propre quelle que soit la méthode utilisée.
Les règles print CSS à mettre en place en priorité
Le point de départ : masquer les éléments qui n'ont pas leur place dans un PDF (menus de navigation, barres latérales, boutons, publicités). Utilisez display: none dans votre media query print pour ces éléments. Définissez ensuite les marges de page avec @page :
@media print {
nav, aside, footer, .no-print {
display: none;
}
body {
font-size: 12pt;
color: #000;
background: #fff;
}
@page {
size: A4;
margin: 20mm 15mm;
}
}La règle @page permet de définir le format (A4, Letter, A3), l'orientation (portrait/landscape) et les marges. Elle est supportée par Chrome et wkhtmltopdf. Puppeteer l'interprète aussi, mais ses propres paramètres PDF priment sur @page si vous les définissez dans le script.
Gérer les sauts de page sans mauvaises surprises
Les propriétés page-break-before, page-break-after et page-break-inside (ou leurs équivalents modernes break-before, break-after, break-inside) contrôlent où les sauts de page se produisent. Pour éviter qu'un titre se retrouve seul en bas de page, utilisez page-break-after: avoid sur les balises de titre. Pour qu'un élément commence toujours sur une nouvelle page, utilisez page-break-before: always.
@media print {
h2, h3 {
page-break-after: avoid;
}
table, figure {
page-break-inside: avoid;
}
.nouvelle-page {
page-break-before: always;
}
}La propriété page-break-inside: avoid est particulièrement utile pour les tableaux et les figures : elle empêche qu'un tableau soit coupé en plein milieu entre deux pages. Pour des documents destinés à être aussi distribués en image, certaines équipes optent pour exporter en image PNG chaque page du PDF, surtout pour des aperçus ou des partages sur les réseaux sociaux.
Polices et couleurs en contexte print
Les polices web (chargées via Google Fonts ou @font-face) ne sont pas toujours disponibles lors de la conversion. Avec wkhtmltopdf, les polices web chargées via URL externe peuvent manquer si le serveur bloque les requêtes. La solution : intégrer les polices en base64 directement dans le CSS, ou utiliser des polices système comme fallback dans votre stack de polices. La librairie jsPDF JavaScript, qui embarque ses propres polices dans le bundle, contourne entièrement ce problème en générant le PDF côté client.
Pour les couleurs, sachez que de nombreuses imprimantes et visionneuses PDF désactivent par défaut les couleurs de fond. Pour forcer leur affichage, ajoutez -webkit-print-color-adjust: exact; print-color-adjust: exact; aux éléments concernés. Puppeteer respecte ces règles si printBackground: true est activé.
Factures, newsletters, archivage : quel outil pour quel usage ?
La méthode optimale dépend de ce que vous convertissez. Une facture générée automatiquement, un email HTML archivé et un rapport d'analyse n'ont pas les mêmes contraintes. J'ai passé quelques années à automatiser ce type de production. Les erreurs que j'ai faites, vous pouvez les éviter.
Générer des factures en PDF depuis du HTML
La génération de factures est un cas d'usage parfait pour Puppeteer ou wkhtmltopdf. Le flux typique : un template HTML avec des variables (nom client, montant, date), un script qui injecte les données et génère le fichier HTML, puis la conversion en PDF. Ce pipeline peut tourner côté serveur et produire des centaines de factures à la minute. Des services dédiés comme convertir HTML en PDF avec Doppio permettent d'externaliser cette étape via une API sans gérer l'infrastructure Chrome.
Pour les factures, la précision du rendu est critique. Préférez Puppeteer pour une fidélité maximale, ou WeasyPrint en Python si vous voulez éviter la dépendance à Chrome. Assurez-vous que vos CSS print incluent des marges adaptées et que les tableaux ont page-break-inside: avoid pour ne pas couper une ligne de commande entre deux pages.
Archiver des newsletters HTML en PDF
J'ai formé plusieurs équipes marketing à ce processus : récupérer les archives HTML des newsletters envoyées et les convertir en PDF pour les conserver dans un système documentaire. Le défi principal est que les newsletters utilisent souvent des mises en page en tableaux (compatibilité email oblige), avec des images hébergées sur des CDN qui peuvent disparaître.
La solution : convertir dans les 24h après envoi, quand toutes les ressources sont encore en ligne. Puppeteer avec waitUntil: 'networkidle0' charge toutes les images avant de générer le PDF. Pour un archivage à long terme, téléchargez aussi les images séparément ou intégrez-les en base64 dans le HTML avant conversion. Ces archives PDF s'inscrivent naturellement dans une démarche de gestion électronique de documents, aux côtés des contrats, des rapports et des courriers numérisés.
Exporter des rapports et tableaux de bord
Pour les rapports avec des graphiques générés en JavaScript (Chart.js, D3.js), wkhtmltopdf peut échouer si les graphiques sont rendus après le chargement de la page. Puppeteer résout ce problème avec waitUntil: 'networkidle0' et, si nécessaire, un délai supplémentaire avec page.waitForTimeout(2000) pour laisser les animations se terminer.
Pour les tableaux de bord larges, pensez à l'orientation paysage (landscape: true dans Puppeteer, ou --orientation Landscape avec wkhtmltopdf). Définissez aussi une largeur de viewport adaptée au format de la page pour éviter que le contenu soit tronqué : await page.setViewport({ width: 1200, height: 800 }).
Conversion par lot : traiter des centaines de fichiers
Pour convertir un grand volume de fichiers HTML, deux approches s'imposent. Avec wkhtmltopdf, le script shell en boucle reste la solution la plus simple et la plus rapide. Avec Puppeteer, on peut paralléliser les conversions en maintenant un pool de navigateurs ouverts, ce qui multiplie le débit par le nombre de workers.
// Puppeteer : conversion parallèle avec pool de pages
const puppeteer = require('puppeteer');
const files = ['doc1.html', 'doc2.html', 'doc3.html']; // liste de fichiers
async function convertAll(files) {
const browser = await puppeteer.launch();
const promises = files.map(async (file) => {
const page = await browser.newPage();
await page.goto(`file://${process.cwd()}/${file}`);
await page.pdf({ path: file.replace('.html', '.pdf'), format: 'A4' });
await page.close();
});
await Promise.all(promises);
await browser.close();
}
convertAll(files);Ce script ouvre toutes les conversions en parallèle. Pour de très grands volumes (1000+ fichiers), segmentez en batches de 10 à 20 pour ne pas surcharger la mémoire du serveur.
Quand la conversion déraille : diagnostic et corrections
Même avec le bon outil, la conversion HTML vers PDF réserve quelques surprises. Images manquantes, polices remplacées, CSS ignoré, sauts de page au mauvais endroit. Chacun a une cause précise et une correction rapide.
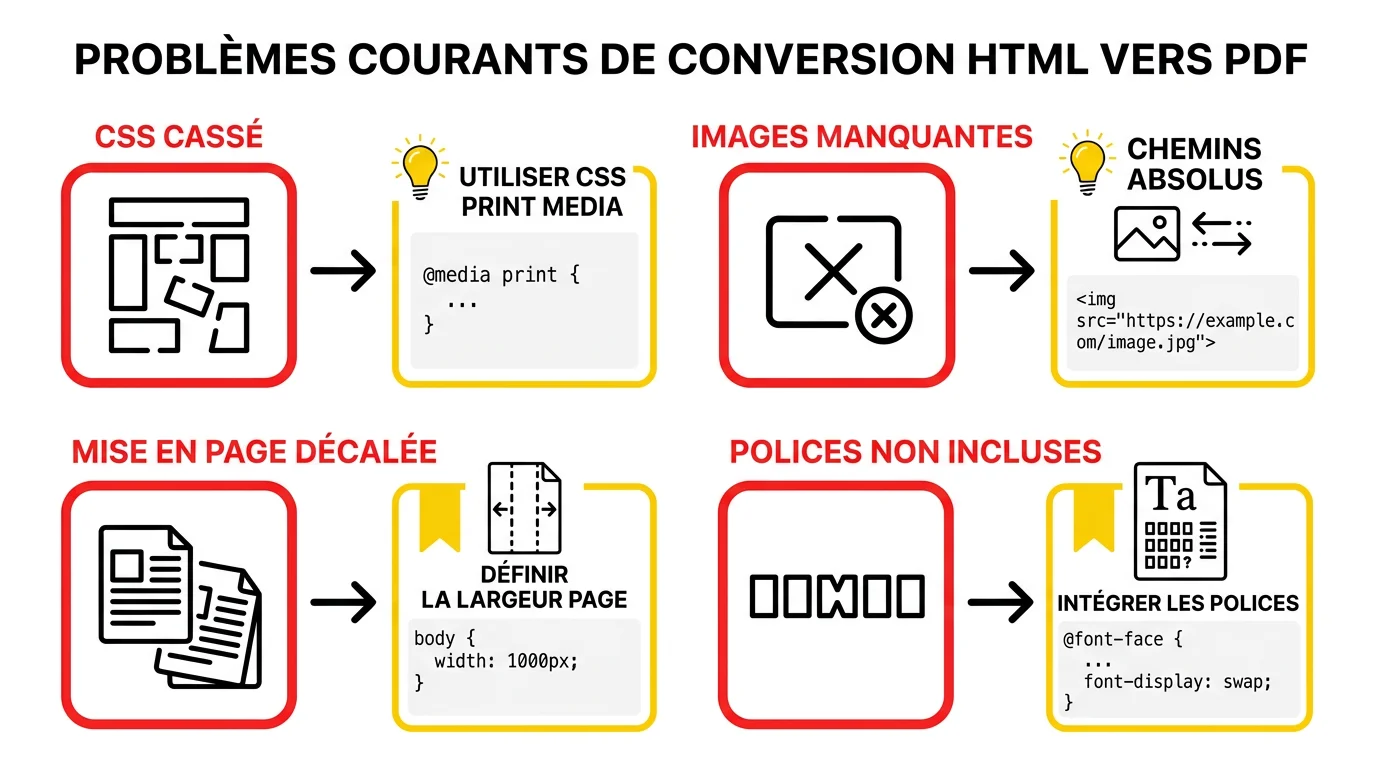
Images manquantes dans le PDF généré
Les images manquantes sont le problème numéro un. La cause la plus fréquente : les chemins relatifs dans le HTML ne sont pas résolus correctement par l'outil de conversion. Avec wkhtmltopdf, utilisez toujours des URLs absolues ou spécifiez le chemin de base avec --base-url. Avec Puppeteer, passez par page.goto('file:///chemin/absolu/vers/le/fichier.html') pour que les ressources relatives soient résolues depuis le bon dossier.
Autre cause : les images servies depuis des CDN avec restrictions CORS ou referrer. Dans ce cas, téléchargez les images localement avant la conversion, ou intégrez-les en base64 directement dans le HTML. Les développeurs travaillant dans l'écosystème Microsoft disposent de bibliothèques spécialisées pour cette étape : le guide sur convertir HTML en PDF avec .NET couvre les cas d'images embedées et les pièges courants des chemins relatifs.
Polices incorrectes ou caractères manquants
Si vos polices personnalisées ne s'affichent pas dans le PDF, c'est généralement parce que l'outil de conversion ne peut pas les charger. Avec wkhtmltopdf, installez les polices directement sur le système (fichiers .ttf ou .otf dans les répertoires système) plutôt que de les charger via @font-face depuis une URL externe. Avec Puppeteer, les polices chargées via Google Fonts fonctionnent si la connexion internet est disponible ; pour un environnement offline, intégrez les polices en base64 dans le CSS.
Pour les caractères spéciaux (accents, caractères asiatiques, symboles), assurez-vous que votre HTML déclare bien <meta charset="UTF-8"> dans le <head>. Sans cette déclaration, certains outils supposent un encodage Latin-1 et produisent des caractères incorrects.
CSS ignoré ou mal interprété
wkhtmltopdf ne supporte pas toutes les propriétés CSS3 modernes. Si votre page utilise des CSS grid complexes, certaines valeurs de flexbox ou des transformations CSS, le rendu peut différer de l'affichage navigateur. La solution : créer une feuille de style alternative pour le print, qui simplifie les mises en page complexes en layouts plus basiques (float ou positionnement classique) mieux supportés par wkhtmltopdf.
Avec Puppeteer, ce problème est rare car il utilise le vrai moteur Chrome. Si le rendu diffère quand même, vérifiez la taille du viewport définie dans votre script : un viewport trop étroit peut faire basculer des mises en page responsive vers leur version mobile, ce qui affecte le résultat final.
PDF trop volumineux
Un PDF généré depuis du HTML peut devenir très lourd si les images ne sont pas optimisées. Compressez vos images avant conversion (format WebP ou JPEG progressif à 80% de qualité), et évitez les images en base64 pour les fichiers lourds car elles augmentent significativement la taille du HTML. Avec Puppeteer, l'option scale permet de réduire le facteur de rendu : scale: 0.8 réduit la taille du PDF d'environ 20% avec une légère perte de qualité.
Pour les PDF destinés à être partagés par email, visez un poids inférieur à 2 Mo. Au-delà, envisagez de compresser le PDF généré avec un outil dédié (Ghostscript en ligne de commande, ou compress-pdf via iLovePDF API).
Contenu JavaScript non rendu
Si votre page HTML utilise JavaScript pour générer ou modifier du contenu (tableaux de bord, graphiques, contenu chargé en Ajax), wkhtmltopdf peut capturer la page avant que le JavaScript ne s'exécute complètement. Activez JavaScript avec --enable-javascript et ajoutez un délai avec --javascript-delay 3000 (3 secondes) pour laisser le temps au contenu de se charger.
Avec Puppeteer, utilisez waitUntil: 'networkidle0' pour attendre la fin des requêtes réseau, et page.waitForSelector('.mon-contenu-chargé') pour attendre qu'un élément spécifique soit présent dans le DOM avant de générer le PDF. Cette approche est bien plus fiable qu'un délai fixe.
Questions fréquentes sur la conversion HTML vers PDF
Comment convertir une page web entière en PDF avec Chrome ?
Ouvrez la page dans Chrome, appuyez sur Ctrl+P (ou Cmd+P sur Mac), sélectionnez "Enregistrer au format PDF" dans le menu "Destination". Dans "Autres paramètres", cochez "Graphiques d'arrière-plan" pour conserver les couleurs et images de fond. Ajustez les marges selon vos besoins, puis cliquez sur "Enregistrer". Le PDF est généré localement sans passer par un serveur tiers.
Quelle est la différence entre wkhtmltopdf et Puppeteer pour la conversion HTML vers PDF ?
wkhtmltopdf utilise une version ancienne de WebKit et ne supporte pas tous les CSS3 modernes. Il est plus léger et simple à déployer. Puppeteer pilote Chrome headless, ce qui garantit un rendu identique à un vrai navigateur, CSS modernes et JavaScript inclus. Pour des pages simples, les deux donnent des résultats proches. Pour des mises en page complexes avec JavaScript, Puppeteer est plus fiable.
Comment convertir plusieurs fichiers HTML en PDF en une seule fois ?
Avec wkhtmltopdf, un script shell en boucle suffit : for f in *.html; do wkhtmltopdf "$f" "${f%.html}.pdf"; done. Avec Puppeteer, vous pouvez paralléliser les conversions en ouvrant plusieurs pages simultanément dans un même navigateur headless. Des outils en ligne comme PDF24 proposent aussi une conversion par lot gratuite pour des besoins ponctuels sans installation.
Pourquoi les images n'apparaissent-elles pas dans le PDF converti ?
La cause la plus fréquente est un chemin d'image incorrect : les images référencées en chemins relatifs ne sont pas trouvées par l'outil de conversion. Utilisez des URLs absolues dans votre HTML, ou spécifiez le chemin de base avec --base-url (wkhtmltopdf) ou file:///chemin/absolu/ (Puppeteer). Les images bloquées par CORS ou des restrictions referrer doivent être téléchargées localement avant conversion.
Comment contrôler les sauts de page dans un PDF généré depuis du HTML ?
Utilisez les propriétés CSS print : page-break-before: always force un saut de page avant un élément, page-break-after: avoid empêche un saut juste après (utile pour les titres), et page-break-inside: avoid empêche qu'un élément soit coupé entre deux pages (idéal pour les tableaux). Ces règles doivent être placées dans un bloc @media print { }.
Quel outil en ligne gratuit est le meilleur pour convertir du HTML en PDF ?
PDF24 est le plus généreux : conversions illimitées, sans limite de taille, avec traitement par lot. Sejda propose trois tâches gratuites par heure avec un support CSS correct. iLovePDF est le plus connu avec une interface claire, mais la version gratuite est limitée à 25 Mo. Pour des données sensibles, évitez tous les outils en ligne et préférez une conversion locale via navigateur ou wkhtmltopdf.
Comment générer automatiquement des factures PDF depuis un template HTML ?
Le flux standard : créez un template HTML avec des variables (nom client, montant, date), injectez les données via un script (Python, Node.js ou PHP), puis convertissez le HTML en PDF avec Puppeteer ou wkhtmltopdf. Ce pipeline peut être déclenché via une API ou un cron job pour générer des centaines de factures automatiquement. WeasyPrint est aussi une excellente option en Python, sans dépendance à Chrome.