Chaque fois que Netflix vous suggère une série au moment précis où vous ne saviez plus quoi regarder, ou que Spotify glisse exactement le bon titre dans votre playlist, ce n'est pas de la magie. C'est un algorithme de recommandation qui tourne en coulisses, analysant des millions de signaux pour anticiper vos envies.
Mais comment fonctionnent-ils vraiment ? Quelles méthodes se cachent derrière ces suggestions apparemment intuitives ? Et surtout, quelles sont leurs vraies limites sur la vie privée et les biais ? Ce guide répond à ces questions.
Qu'est-ce qu'un algorithme de recommandation ?
Un algorithme de recommandation analyse votre comportement passé pour deviner ce que vous voulez maintenant. C'est automatique, silencieux, et ça tourne en permanence.
Concrètement, le système collecte des signaux : durée de visionnage, items ignorés, notes, mises en pause. Ces données alimentent un modèle mathématique qui calcule un score de pertinence pour chaque item. Celui avec le score le plus élevé remonte en tête de liste.
Le terme "algorithme" peut intimider, mais l'idée de base est aussi ancienne que le commerce : un bon bouquiniste recommande à ses clients habitués des livres qu'ils n'auraient jamais trouvés seuls, parce qu'il connaît leurs goûts. L'algorithme fait la même chose, mais à l'échelle de plusieurs centaines de millions d'utilisateurs simultanément.
Quiz algorithmes de recommandation
Quelle plateforme utilisez-vous le plus ?
Choisissez votre plateforme
Composition de l'algorithme
Les grandes méthodes de filtrage
Il n'existe pas un seul type d'algorithme de recommandation. Chaque approche a ses angles morts, et les systèmes modernes mixent plusieurs méthodes pour compenser.
Le filtrage collaboratif : la sagesse collective
Le filtrage collaboratif est l'approche la plus répandue. Elle part d'un constat au fondement même des systèmes de recommandation modernes : si deux utilisateurs ont aimé les mêmes choses dans le passé, ils ont probablement des goûts similaires. Le système identifie des "voisins" proches de vous dans une matrice de préférences, puis remonte les items qu'ils ont appréciés mais que vous n'avez pas encore vus.
Il existe deux variantes. Le filtrage collaboratif user-based compare les utilisateurs entre eux. Le filtrage collaboratif item-based compare les items entre eux : si vous aimez A et que B ressemble à A dans les comportements d'autres utilisateurs, il vous propose B.
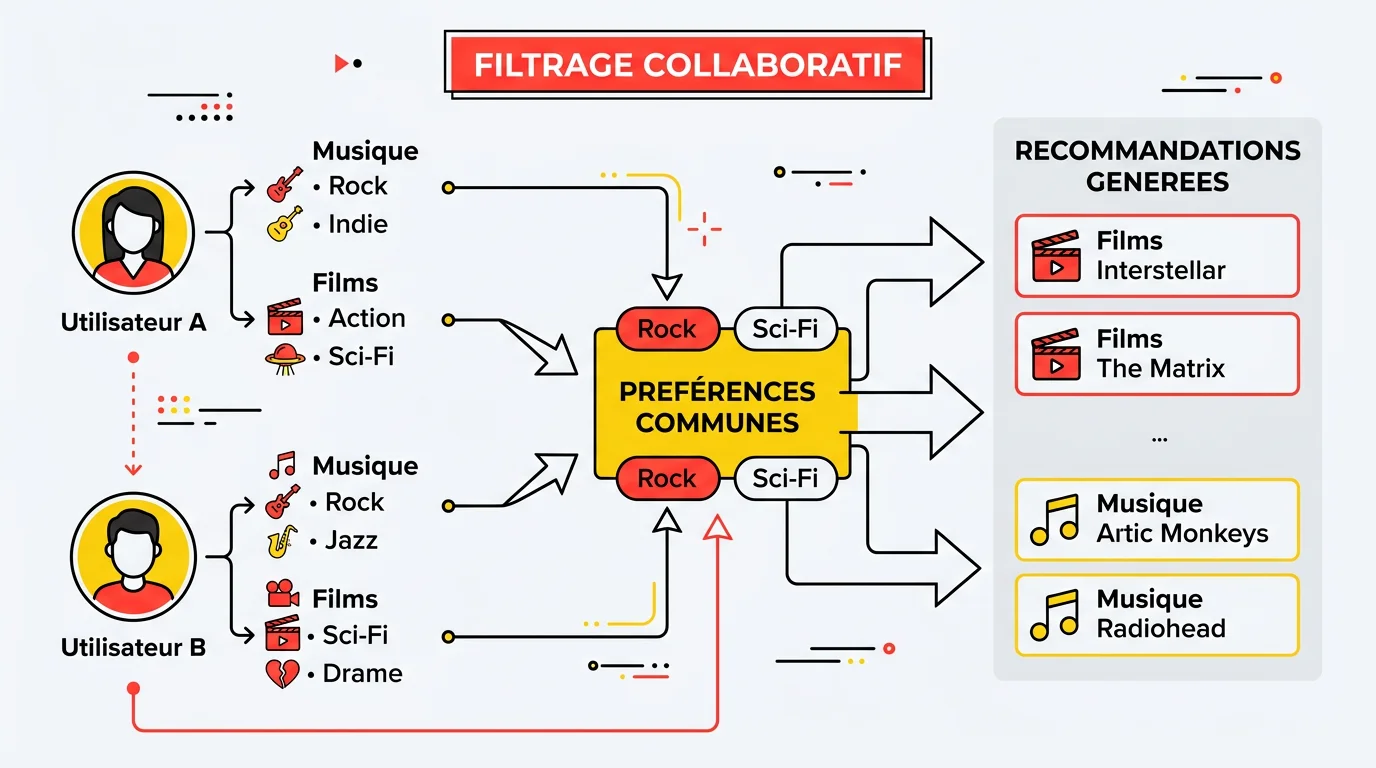
L'avantage principal : cette méthode peut recommander des contenus très différents dans leur nature, mais que votre "jumeau de goût" a adorés. C'est elle qui génère les vraies surprises, les découvertes hors des sentiers battus. Sa limite ? Il faut suffisamment de données sur l'utilisateur pour trouver des voisins fiables.
Le filtrage par contenu (content-based) : l'analyse des attributs
Le filtrage par contenu adopte une approche radicalement différente. Plutôt que de regarder ce qu'ont fait les autres utilisateurs, il analyse les caractéristiques intrinsèques des items que vous avez appréciés. Si vous écoutez souvent de la guitare acoustique en tempo lent, le système cherche d'autres morceaux partageant ces attributs.
Pour la musique, ces attributs couvrent le tempo, la tonalité, l'instrumentation. Pour un film, ce sera le réalisateur, les acteurs, l'époque. Chaque item est représenté par un vecteur de caractéristiques, et le système calcule une distance entre ce vecteur et votre profil.
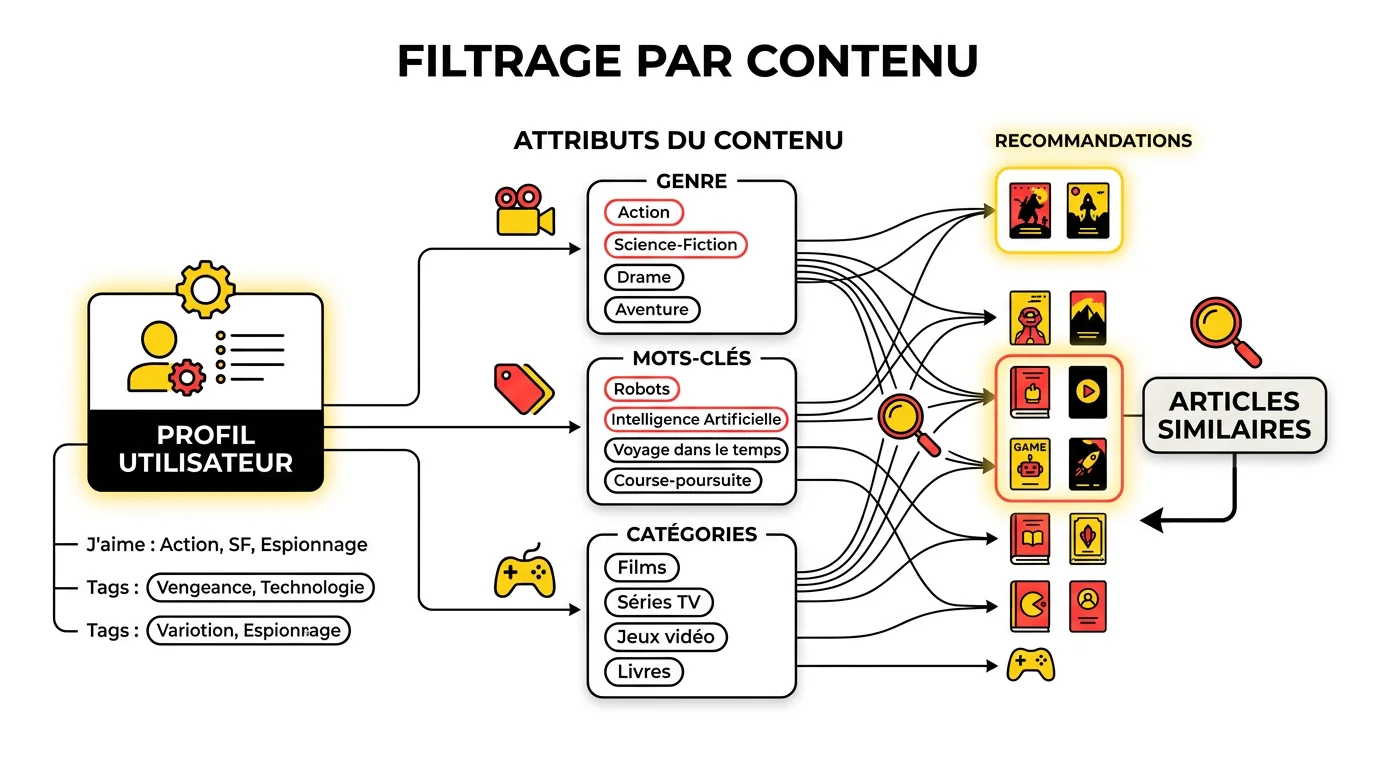
L'avantage de cette méthode : elle fonctionne dès le premier jour si l'on dispose d'un profil minimal, sans dépendre d'autres utilisateurs. Sa limite est réelle : elle a tendance à enfermer dans le connu. Si vous aimez les thrillers nordiques, elle vous en recommandera encore, sans jamais proposer autre chose.
Le filtrage hybride et le deep learning
La quasi-totalité des grandes plateformes utilisent aujourd'hui des approches hybrides : filtrage collaboratif et content-based, combinés pour atténuer leurs limites respectives. Netflix fait tourner simultanément des dizaines de modèles dont les scores sont ensuite agrégés.
Le deep learning a profondément changé le domaine depuis 2016. Les réseaux de neurones, les transformers et les embeddings en particulier, représentent utilisateurs et items dans des espaces vectoriels de très haute dimension, capturant des similarités que les méthodes classiques ne détectaient pas. YouTube a basculé vers un modèle à deux étapes : un réseau de génération de candidats, puis un réseau de classement fin.
Le tableau ci-dessous résume les quatre grandes approches et leurs caractéristiques clés.
| Méthode | Principe | Avantages | Limites | Utilisé par |
|---|---|---|---|---|
| Filtrage collaboratif | Similarité entre utilisateurs ou items | Découvertes surprenantes, pas besoin de décrire les items | Cold start, nécessite beaucoup de données | Amazon, Last.fm, Netflix (partiel) |
| Content-based | Analyse des attributs des items aimés | Fonctionne dès le début, explicable | Sur-spécialisation, manque de sérendipité | Spotify (Audio features), Pandora |
| Hybride | Combinaison de plusieurs modèles | Meilleure précision, compense les faiblesses | Complexité, coût computationnel | Netflix, YouTube, Apple Music |
| Deep Learning | Réseaux de neurones, embeddings | Capture des patterns complexes, très haute précision | Boîte noire, données massives requises | TikTok, YouTube, Google Discover |
Netflix, Spotify, TikTok, Amazon : comment chaque plateforme l'utilise ?
Chaque grande plateforme a construit son propre système, taillé pour son métier et ses objectifs spécifiques. Ces implémentations concrètes montrent ce que ces algorithmes font vraiment, loin des communiqués officiels.
Netflix : 80 % des contenus regardés viennent des recommandations
Netflix revendique que 80 % des heures de visionnage viennent directement de ses algorithmes, pas de recherches actives. C'est un chiffre souvent cité dans les analyses des algorithmes de recommandation sur les plateformes de streaming. Le modèle de Netflix surveille tout : titres terminés, abandons au bout de dix minutes, langue préférée, et même la vignette sur laquelle vous avez cliqué.
Ce dernier point est fascinant : Netflix teste des centaines de vignettes différentes pour le même film, et l'algorithme choisit celle à vous afficher selon votre profil. Si vous regardez beaucoup de films avec des acteurs spécifiques, la vignette mettant en valeur cet acteur sera privilégiée pour vous, même si ce n'est pas la vignette standard.
Netflix intègre aussi le contexte temporel. Une recommandation faite un vendredi soir à 22h ne sera pas la même qu'un mercredi après-midi, car les comportements de visionnage diffèrent selon le moment de la semaine.
Spotify : les "Audio Features" et la découverte musicale
Spotify a développé une approche particulièrement sophistiquée qui mêle analyse audio et filtrage collaboratif. Chaque morceau est analysé selon des dizaines de paramètres acoustiques : énergie, dansabilité, valence (caractère positif ou négatif), acousticité, tempo, modalité. Ces attributs alimentent le filtrage content-based.
Mais le vrai succès de Spotify tient à ses playlists algorithmiques. "Discover Weekly" analyse ce que vos "jumeaux musicaux" écoutent mais que vous n'avez pas encore exploré. "Daily Mix" combine vos artistes favoris avec des recommandations proches. "Release Radar" suit les sorties de vos artistes suivis. Ces formats couvrent des intentions d'écoute très différentes.
J'utilise Spotify depuis 2013 et je constate que la qualité des recommandations a radicalement changé autour de 2016-2017, précisément au moment où Spotify a commencé à intégrer des techniques de deep learning. Avant, les suggestions restaient dans un périmètre étroit. Aujourd'hui, Discover Weekly m'a fait découvrir des artistes que je n'aurais jamais trouvés par mes propres recherches.
TikTok : le modèle de recommandation le plus agressif du marché
TikTok a changé quelque chose de fondamental dans la recommandation. Contrairement à Netflix ou Spotify où vous choisissez activement ce que vous lancez, TikTok fonctionne en flux continu : le contenu défile et vous interagissez ou pas. Cela génère un signal comportemental extrêmement dense et précis.
L'algorithme de TikTok donne un poids très élevé au taux de visionnage complet. Si vous regardez une vidéo jusqu'au bout, ou si vous la revoyez, c'est un signal fort. Si vous passez à la suivante après deux secondes, c'est aussi un signal fort en négatif, un mécanisme que l'algorithme TikTok exploite pour affiner le profil utilisateur en temps réel. La plateforme peut ainsi construire un profil très précis en quelques dizaines de vidéos seulement, ce qui résout en partie le problème du cold start.
C'est aussi pour cette raison que TikTok est régulièrement pointé du doigt sur les questions de dépendance et d'enfermement : son algorithme est optimisé pour maximiser le temps passé sur la plateforme, pas nécessairement pour votre bien-être.
Amazon : recommandation orientée conversion
Amazon a popularisé le filtrage collaboratif item-based dès les années 2000 avec son fameux "les clients ayant acheté cet article ont également acheté". Leur objectif diffère de celui des plateformes de divertissement : maximiser la conversion, pas l'engagement émotionnel.
Le système d'Amazon intègre tout : consultations, ajouts au panier, achats, notes, et surtout le contexte d'achat (produits fréquemment associés, accessoires). La recommandation est donc à la fois éditoriale ("vous pourriez aimer") et commerciale ("achetez aussi ceci").
Amazon a publié des données internes montrant que 35 % de son chiffre d'affaires est directement attribuable à ses moteurs de recommandation. C'est un argument économique imparable qui explique les investissements colossaux dans ce domaine.
Le problème du cold start : que se passe-t-il pour un nouvel utilisateur ?
Le cold start est l'un des défis techniques majeurs des systèmes de recommandation. Il désigne la situation où le système dispose de trop peu de données sur un utilisateur ou un item pour faire des recommandations pertinentes. C'est le problème du premier jour : que recommander à quelqu'un dont on ne sait encore rien ?
Il existe en réalité trois types de cold start. Le cold start utilisateur : un nouvel inscrit sans historique. Le cold start item : un nouveau contenu ou produit sur lequel personne n'a encore interagi. Le cold start système : une toute nouvelle plateforme sans données du tout.
Les plateformes ont développé plusieurs stratégies pour y répondre. La plus simple consiste à poser des questions d'onboarding : Netflix demande vos genres préférés lors de l'inscription. Spotify vous fait sélectionner des artistes. Ces quelques signaux permettent de construire un profil initial.
Une autre approche repose sur la popularité : quand on ne sait pas quoi recommander à un utilisateur, on lui propose ce qui plaît au plus grand nombre dans sa démographie ou sa région. C'est une recommandation "sûre" mais peu personnalisée, ce qui illustre bien comment l'IA s'adapte aux usages selon les contraintes de chaque plateforme. TikTok résout le cold start utilisateur plus vite que les autres grâce à la densité des signaux comportementaux générés par le flux continu.
Pour le cold start item, les plateformes utilisent les métadonnées : genre, tags, description, attributs techniques. Un film tout juste sorti sur Netflix sera d'abord recommandé selon ses caractéristiques déclarées, puis les modèles prendront le relais dès que suffisamment d'utilisateurs l'auront regardé.
Personnellement, j'ai observé ce phénomène chaque fois que j'ai créé un nouveau compte test sur ces plateformes pour évaluer leur expérience. Les premières recommandations sont toujours génériques, parfois décevantes. Ça s'affine rapidement, en général dès la deuxième ou troisième session.
Bulles de filtre et biais algorithmiques
Eli Pariser a popularisé le concept de "bulle de filtre" en 2011 dans son livre éponyme. L'idée est que les algorithmes, en cherchant à vous montrer ce que vous aimez, finissent par vous enfermer dans une chambre d'écho où vous n'êtes plus exposé qu'à des contenus confirmant vos opinions et préférences existantes.
Cette critique est fondée, mais elle mérite d'être nuancée. Les bulles de filtre existent, mais leur impact, bien visible dans la plupart des outils d'intelligence artificielle grand public, dépend beaucoup de la nature du service et de ses objectifs business. Une plateforme musicale vous enfermera dans un genre. Un réseau social d'information peut avoir des conséquences bien plus sérieuses sur la polarisation politique.
Les biais algorithmiques sont un problème distinct mais connexe. Ces biais viennent des données d'entraînement : si le catalogue d'une plateforme était historiquement dominé par des artistes masculins blancs anglophones, le modèle entraîné sur cet historique aura tendance à les surreprésenter dans les recommandations. Les biais humains présents dans les données se retrouvent amplifiés dans les sorties de l'algorithme.
Les effets concrets sont documentés. Des études ont montré que YouTube peut faire glisser un utilisateur vers des contenus de plus en plus radicaux via ses recommandations, un phénomène analysé en détail dans le guide sur les modèles de machine learning qui décortique les dynamiques d'optimisation par renforcement. Amazon a été critiqué pour des systèmes de recommandation d'emploi qui défavorisaient les candidatures féminines, parce que les données historiques d'embauche étaient biaisées.
La prise de conscience est réelle dans l'industrie, même si je reste sceptique sur les motivations. Plusieurs plateformes ont introduit des mécanismes de diversification intentionnelle : l'algorithme est contraint d'injecter une proportion de contenus hors du périmètre habituel de l'utilisateur. Spotify l'appelle "taste adventurousness". C'est une façon d'atténuer la bulle sans la supprimer.
RGPD, DSA et transparence algorithmique : quel cadre légal ?
Les algorithmes de recommandation sont désormais au centre des préoccupations réglementaires européennes. Deux textes structurent ce cadre : le RGPD pour la protection des données personnelles, et le DSA (Digital Services Act) entré en application en 2024 pour la régulation des très grandes plateformes.
Ce que dit le RGPD sur les recommandations personnalisées
Le RGPD encadre directement les algorithmes de recommandation. En pratique, les plateformes doivent informer les utilisateurs du profilage qui leur est appliqué, leur donner un droit d'opposition, et respecter des règles précises sur la durée de conservation des données.
L'article 22 du RGPD est particulièrement pertinent : il prévoit un droit à ne pas faire l'objet de décisions entièrement automatisées ayant des effets significatifs. Dans le contexte d'une recommandation musicale, l'impact est limité, comme le soulignent les recommandations de la CNIL sur l'IA qui distinguent les usages selon leur niveau de risque. Mais dans des contextes comme le crédit, l'emploi ou l'assurance, ce droit prend toute son importance.
Le DSA et les obligations de transparence algorithmique
Le Digital Services Act impose de nouvelles obligations aux très grandes plateformes (plus de 45 millions d'utilisateurs en Europe). Ces plateformes doivent désormais proposer au moins un système de recommandation non basé sur le profilage : par exemple, un fil chronologique ou un classement par popularité neutre.
Elles doivent aussi publier des rapports de transparence sur leurs algorithmes. Les utilisateurs ont le droit de savoir pourquoi un contenu leur est recommandé, une exigence qui touche aussi la personnalisation marketing des grandes plateformes, avec une explication en langage clair. TikTok, YouTube, Facebook et les autres ont dû adapter leurs interfaces pour afficher ces explications, même si leur niveau de détail reste souvent insuffisant.
Le DSA prévoit aussi un accès aux données pour les chercheurs accrédités, afin de permettre une évaluation indépendante des risques systémiques. C'est une avancée significative pour l'audit algorithmique, même si les modalités pratiques restent en cours de définition.
Depuis que je couvre l'actualité tech sur DjVuZone, j'ai vu ce dossier évoluer considérablement. Il y a encore trois ans, parler de "régulation algorithmique" semblait utopique. Aujourd'hui, c'est une réalité juridique opérationnelle en Europe, même si l'application reste inégale.
IA générative, explicabilité, vie privée : vers quels algorithmes demain ?
L'IA générative et la pression réglementaire sont en train de remodeler les algorithmes de recommandation plus vite que prévu. Ce qui change vraiment, et pourquoi ça compte pour les utilisateurs.
Quand l'IA générative change les règles du jeu
L'IA générative change la nature même de la recommandation. Jusqu'ici, un algorithme sélectionne parmi des items existants. Avec les modèles génératifs, la frontière devient floue : Spotify expérimente des playlists musicales entièrement générées selon un mood, sans que les morceaux proposés soient tous des titres "existants" au sens traditionnel.
Les LLM (grands modèles de langage) ouvrent une autre possibilité : des interfaces de recommandation conversationnelles. Au lieu de recevoir passivement des suggestions, l'utilisateur peut décrire en langage naturel ce qu'il cherche : "un film d'action des années 90 avec une forte dimension émotionnelle, pas trop violent". Le modèle interprète cette requête et génère une sélection personnalisée.
Amazon et Netflix testent activement ces interfaces. Google Discover intègre déjà des signaux sémantiques issus de modèles de langage, tout comme le moteur de recommandation Amazon, pour enrichir ses suggestions de manière contextuelle. On passe d'un algorithme qui prédit à un assistant qui comprend.
Pourquoi expliquer les algorithmes devient obligatoire ?
L'explicabilité des algorithmes est devenue une priorité, en partie poussée par la réglementation. Le concept de XAI (eXplainable AI) cherche à rendre compréhensibles les décisions des modèles de deep learning, qui sont par nature des boîtes noires. Des techniques comme LIME ou SHAP permettent d'identifier quels attributs ont le plus contribué à une recommandation particulière.
En pratique, cette exigence se traduit par des mentions du type "Parce que vous avez regardé X" ou "Populaire dans votre région". Ces explications restent très superficielles au regard de la complexité réelle des modèles, mais c'est un premier pas vers une recommandation plus transparente.
Peut-on recommander sans tout surveiller ?
Le modèle dominant de collecte centralisée de données personnelles est sous pression croissante. Des approches alternatives émergent, comme le federated learning, dont le principe rejoint les orientations de l'approche européenne de l'IA en matière de minimisation des données collectées. Google utilise cette technique pour certaines fonctionnalités de Gboard sur Android.
Une autre piste est la recommandation différentiellement privée : des mécanismes mathématiques garantissent qu'il est impossible de retrouver les données d'un utilisateur individuel à partir du modèle, même si on y accède directement. Ces approches sont encore peu déployées, mais c'est probablement là que se trouve la réponse sérieuse : personnaliser sans tout collecter.
La question de fond reste entière : peut-on faire de la bonne recommandation sans surveillance massive ? Les expériences en cours suggèrent que oui, partiellement. Mais il faudra probablement accepter une légère dégradation de la précision en échange d'une bien plus grande protection de la vie privée. C'est un arbitrage que la société devra finir par trancher collectivement.
Questions fréquentes sur les algorithmes de recommandation
Comment un algorithme de recommandation apprend-il mes goûts ?
L'algorithme collecte vos interactions : ce que vous regardez, combien de temps, ce que vous notez positivement ou négativement, ce que vous ignorez. Ces signaux comportementaux alimentent un modèle mathématique qui met à jour votre profil en temps réel. Plus vous utilisez la plateforme, plus le profil est précis et les recommandations pertinentes.
Peut-on désactiver les recommandations personnalisées ?
Oui, le RGPD et le DSA imposent aux plateformes de proposer une alternative non personnalisée. Sur YouTube, vous pouvez désactiver l'historique de visionnage. Sur TikTok, il est possible de limiter la personnalisation dans les paramètres de confidentialité. Netflix ne propose pas d'option aussi directe, mais vous pouvez effacer votre historique, ce qui réinitialise partiellement les recommandations.
Pourquoi voit-on toujours les mêmes types de contenus ?
C'est l'effet bulle de filtre. L'algorithme optimise la pertinence à court terme en restant dans ce qu'il sait que vous aimez. Pour en sortir, cherchez activement des contenus différents, notez explicitement ce que vous n'aimez pas, et exploitez les playlists ou catégories thématiques qui sortent du périmètre habituel. Certaines plateformes proposent des modes "aventure" ou "découverte" qui injectent intentionnellement de la diversité.
Les algorithmes de recommandation sont-ils dangereux ?
Ils présentent des risques réels documentés : enfermement dans des bulles d'opinion, amplification de contenus extrêmes, dépendance comportementale (surtout sur TikTok et YouTube). Ces risques varient selon les plateformes et leurs objectifs d'optimisation. Le DSA européen impose depuis 2024 une évaluation des risques systémiques aux très grandes plateformes, avec obligation d'y remédier.
Qu'est-ce que le problème du cold start ?
Le cold start désigne la difficulté d'un algorithme à faire des recommandations pertinentes quand il manque de données sur un nouvel utilisateur ou un nouvel item. Les plateformes le résolvent via des questions d'onboarding, en s'appuyant sur la popularité générale, ou en analysant les métadonnées déclaratives d'un contenu avant qu'il accumule des interactions réelles.
Comment TikTok personnalise-t-il si vite le contenu ?
TikTok exploite le fait que le contenu défile en flux continu. Chaque pause, chaque visionnage complet, chaque replay est un signal immédiat. La densité de ces micro-interactions permet au modèle de converger vers un profil précis en quelques dizaines de vidéos seulement, là où Netflix a besoin de plusieurs séances de visionnage. C'est techniquement efficace, mais aussi ce qui rend l'application aussi addictive.
Quelle différence entre filtrage collaboratif et filtrage par contenu ?
Le filtrage collaboratif s'appuie sur les comportements d'autres utilisateurs similaires à vous : il recommande ce qu'ils ont aimé et que vous n'avez pas encore vu. Le filtrage par contenu analyse les attributs des items que vous avez appréciés et cherche d'autres items partageant ces caractéristiques. Le premier génère de meilleures surprises, le second fonctionne mieux quand peu de données utilisateurs sont disponibles.